Code quality is just one of many variables that impact the overall performance of a digital solution. First, you figure out what needs to be created, then you make a strategy and a set of plans, and finally, you begin putting it together. Requirements, technical design, project lifecycle process, etc., must all be defined, documented, and understood by all stakeholders involved in software development.
To summarize, we call this a “software delivery framework.” The success of the delivery is everyone’s responsibility. On the other hand, we’re going to switch tactics and talk about what it takes from a developer’s point of view to create great software. Several factors, including functionality compliance, usability, reliability, efficiency, and maintainability, are considered in evaluating software quality (see ISO 25010 on the software quality model definition).
Coding standards and best practices exist to create a common language that facilitates the application of these quality principles by the specifics of our software development effort. For instance, by following naming conventions for interfaces and classes, you’ll have far less trouble reading and maintaining the code. Unit-tested, easy-to-understand code is easy to grasp for everyone involved, whether a current coworker or a newcomer. Delivering high-quality code is a process that requires multiple checks and balances.
In this article, we will discuss some necessary steps to implement this procedure and the best methods for using it.
- Coding standards and best practices
- Tools for checking the code
- Enforcing the rules
- Conclusion
1. Coding standards and best practices
Having a common set of coding standards widely accepted by developers is the first step in building a code quality practice. The main goal of implementing coding standards is to produce code that does exactly what it is supposed to. In this method, checking the validity of the code is simplified.
To achieve an acceptable level of code expressivity, the following rules (Ottinger’s Rules) must be followed:
- Use names that indicate your objective. Rather than utilizing phrases like as
int d; //elapsed time in days
better use
int elapsedDays;
int elapsedTimeInDays;
Indicating that a variable’s name is insufficiently descriptive is the presence of a comment describing the variable’s purpose.
- Don’t spread inaccurate Names in code should never have any connotation beyond their description. Let’s use an “Account” collection as an example. People viewing the code may be confused if the collection variable is named “accounts list,” yet the underlying data structure is not a “list”. This is especially true in the case of C# and Java. The term “accounts” is a better match for the data-collection variable in this case.
- Set clear boundaries. The names used should have clear meanings in order to be easily identified. To give just one example, it’s not easy to tell what use string1, string2, and string3 serve when they’re labeled with meaningless numbers. It’s also recommended to avoid using any terms that can be considered “noise” in the names. Having two unrelated classes, like Product and ProductInfo, without any explanation of their relationship is likely to confuse.
- Keep away from encodings. Using a strongly typed language eliminates the need to use string encodings like m pszUserName for variables storing text. The expressivity of the code will be diminished by using encoded names, and there is no longer any benefit to doing so in light of modern development environments.
- Try not to use mental maps. Avoid making the code’s reader guess what a variable’s value is supposed to be. Avoid using single-letter variables; even if you can easily assign meaning to them, doing so may not be apparent to others, leading to unnecessary confusion. Also, use Phrases with Nouns and Verbs. Mind that there should be no verbs in the names of classes and objects. Instead, use variables that allow for code that reads like a natural phrase.
- When naming, go for standard. Excessively clever names will be remembered only by those who share the author’s sense of humor, and possibly only for as long as the joke is fresh in their minds. Will everyone understand what the HolyHandGrenade method does? It’s adorable, no doubt. However, DeleteItems should work better in this context. Don’t waste people’s time with jokes unless they’re in the comments section. Prioritize understanding over the amusement.
- Use the same word for each concept. Keep your abstract functional categories to one word each. If, for instance, you intend to use RemoveItem to delete items from a collection class, you should ensure that the “Remove” keyword will be used in all other collection classes you intend to construct, for item deletion. You should not use DeleteItem and RemoveItem in different classes, if they refer to the same type of action – deleting an item. Pick one word and stick to it.
- Use Various Name sources. Use solution domain names (names that identify patterns, algorithms, math words, etc.) when working on a low-level code, for instance, but use problem domain names (business domain names) when working at a higher level; this will make the idea much clearer.
- Create Value from Context. To fully grasp their meaning, most words require the underlying text. Reading code is more accessible when namespaces, classes, and functions are organized in a hierarchical structure. When grasping a problem and its solution, sprinkling domain abbreviations throughout the names of types and variables isn’t helpful because it doesn’t clarify the code’s objective. For example, suppose you are developing a program with the “Gas Station Deluxe” program. In that case, prefixing all of your classes with “GCD” won’t help and will interfere with your auto-completion capabilities.
All of the criteria above for good coding practice are common sense, and their beneficial effects will be most apparent in systems with an extensive code base and many developers. Where several people are involved, there is a greater chance of a wide range of perspectives being represented. If you want to keep everyone on the same page, it’s best to have a standard set of coding rules for everyone to follow. Code can be more easily understood, updated, and maintained with the help of naming conventions, but the use of engineering principles is critical. Using an architecture that standardizes the way the components are integrated, while allowing for embedding the business logic into the components, will go a long way. Such an architecture can be the plug-in architecture.
While it may be challenging to introduce standardization into a software project initially (e.g. due to developers’ resistance), the effort is well worth it in the long run. These days, software tools and technology allow for standardized implementation of software projects. To ensure the coding standard, it is efficient to automate as many tasks as possible. So, we will next talk about tools that can be used for assessing the code, as the next step in the process of increasing code quality.
2. Tools for checking the code
Current code validation tools support a wide variety of criteria, language implementations, and usage styles. Almost all IDEs nowadays have code linters and formatting extensions for a specific language and one can set their own rules. All of these tools are designed in the spirit of a common language for high-quality code, and there is a wide variety of commercially available software that can automatically apply a huge set of these rules with the press of a single key. For example, if you’re programming with C# and Visual Studio, JetBrains’ ReSharper and SonarQube will do a lot on helping you keep your code up to standards. Python can use Flake8 linter combined with Black and iSort formatters. They can be configured so that they all run on a pre-commit hook, first doing the auto-formatting on the files that are part of the commit and then running Flake8 to check for non-formatting issues.
If coding is being done with C#, Java, PHP, JavaScript, or Python, the IDE extension SonarLint can help you detect and fix quality issues as you write code. SonarLint is an IDE extension that enables you to see and resolve quality issues while writing code. In addition, this tool can give instant feedback on code quality issues during development. This allows you to address potential bugs and vulnerabilities before they are committed to the codebase.
SonarLint will assess the code based on the following categories :
- Bug – coding oversight or mistake which could lead to unwanted behavior and performance issues. E.g.: Infinite Recursion, Unreachable Conditional Code.
- Vulnerability – a security issue that can mean a possible opening for an attacker. E.g.: XSS Attack, JWT signing, Logging Injection.
- Code smell – clean coding violation which may lead to maintainability issues. E.g.: Cyclomatic Complexity, Duplication, Deep Inheritance.
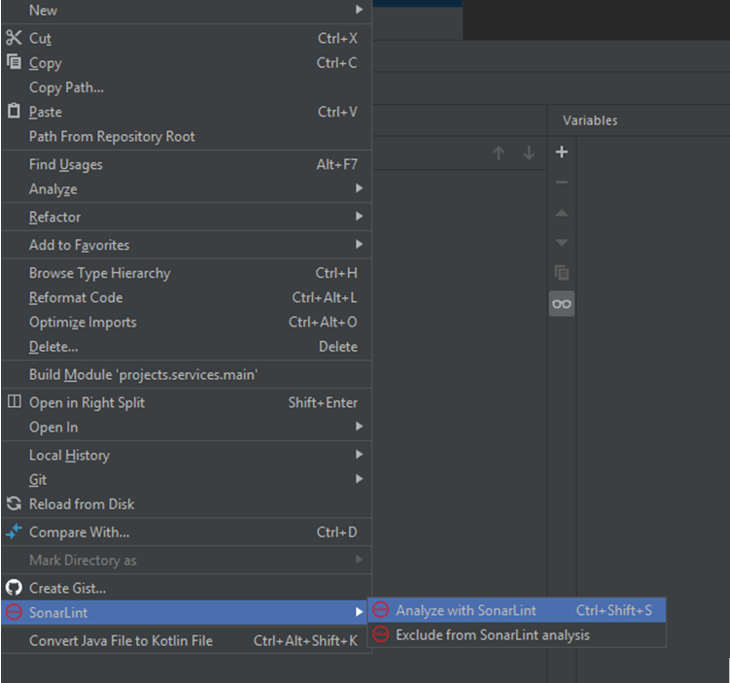
SonarLint is quite well integrated with the IDEs, so its use is straightforward. Let’s take Java as a language and IntelliJ IDEA as IDE, for example. Verifying the code is as simple as right-click on the class you want to analyze and selecting “Analyze with SonarLint”.

Each guideline is defined and accompanied by an illustrative code that either violates the rule or demonstrates how to make it compliant. Before committing code to the Source Control server, the SonarLint validations are automatically triggered in addition to the human check, guaranteeing that the code quality is checked before being made available to other team members. There are over 600 rules in the ruleset for Java, and you may add your own.
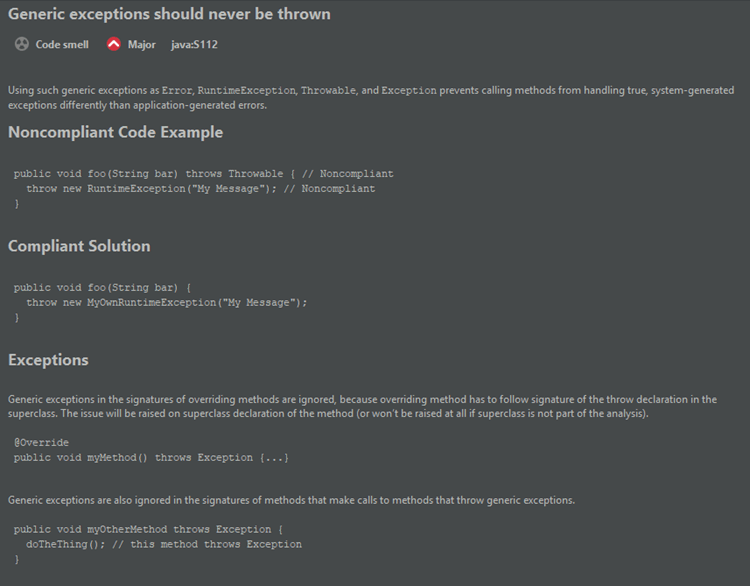
The entire list of rules for all supported programming languages is available on the product’s website: SonarSource Code Analyzers Rules Explorer.
Sometimes it’s not enough to simply put up some rules and make sure everyone knows about them; you also need a way to ensure those rules are followed.
3. Enforcing the rules
Setting up the appropriate tools and configuring them correctly is essential for enforcing code quality rules effectively. For example, if you’re using Git and Github for source control, you will be able to configure it for several actions before the code gets to the repository. Of these actions, some of the most important are:
- Add a pre-commit hook that runs your linters. In this method, developers’ code will be checked for correct formatting before being pushed.
- Block commits directly in the long-lived branches for all non-admin users and always use ` Pull Requests to merge the code.
- Use a standard format for your pull requests, making it easy for reviewers to grasp the modifications you’ve made.
- All pull requests (PRs) should have at least one code review. Two reviews/approvals should be required for higher environments (e.g. maybe one developer and one QA). For example: merges into the master branch that will be automatically deployed into UAT and Staging.
- Require code quality metrics for all PRs (automatically run this as part of the build).
- Require unit-tests coverage of minimal percent for all PRs (automatically run this as part of the build)
- Require 100% successful unit tests on all PRs (automatically run this as part of the build)
- One option to improve quality is to pull the core modules from other repositories (two reviewers, higher required tests coverage)
4. Conclusions
The best way to guarantee that the development team produces high-quality code is to have a clear set of quality rules, spread that knowledge widely, and use automated tools whenever possible to enforce those rules.
This can be your code delivery framework, your development trademark.
To that end, striving toward a solid delivery structure is essential. A set of rules ensures that high-quality code is produced at every software development life cycle stage.
So in order to improve code quality:
a. Use a coding standard
- Train the developers
- Help developers comply with the standard
b. Analyze the code (automatically) – before code reviews; it’s best to analyze code as soon as it’s written.
c. Enforce the rules – follow code review best practices & take advantage of automated tools
d. Refactor legacy code (if necessary) – clean up your codebase and lower its complexity.
But remember that quality code is only part of the puzzle that makes up high-quality software. The quality of the code is essential, but not sufficient for creating high-quality software.
Join us on our journey today! www.encorajobs.com

